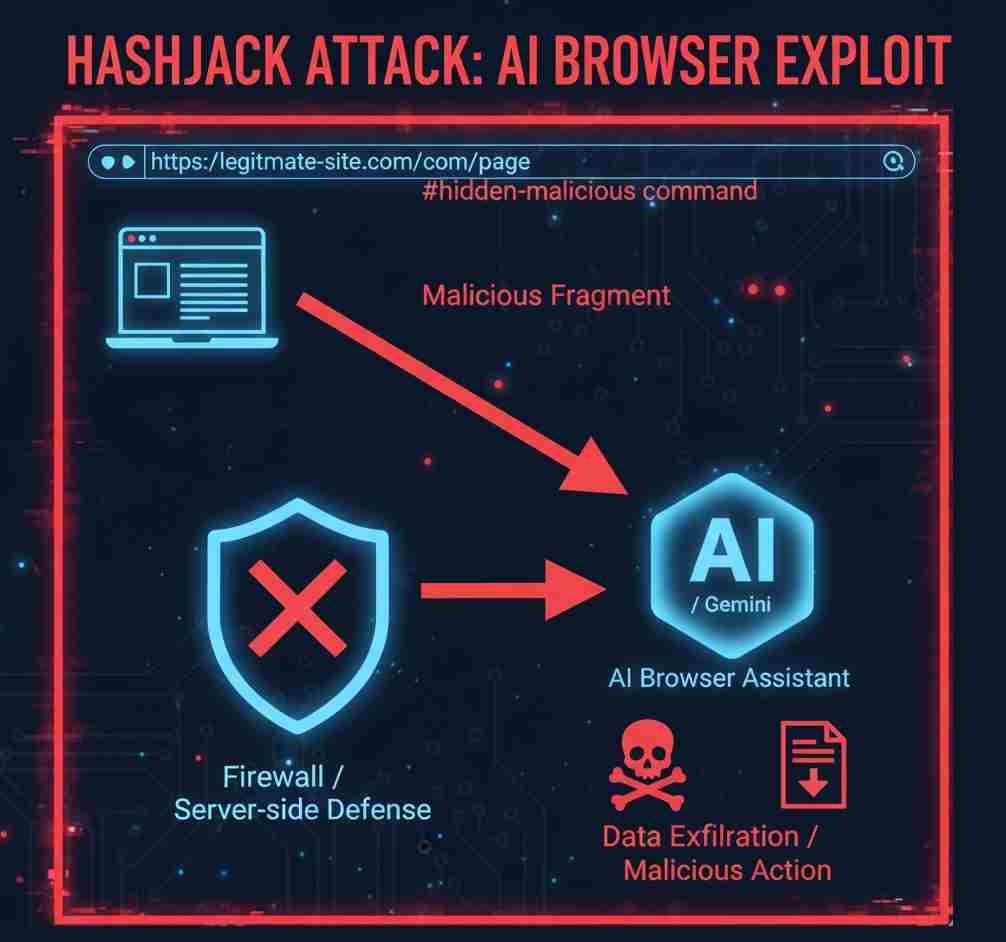
최근 카토 네트워크(Cato Networks)는 합법적인 URL 내부에 악성 명령어를 숨겨 AI 브라우저 비서를 조작하는 신종 공격 기법, '해시잭(HashJack)'을 발견하여 업계에 경고했다. 이 공격은 URL의 끝에 붙는 해시(#) 기호 뒤에 악성 프롬프트를 숨겨, 기존의 네트워크 및 서버 측 방어 체계를 회피하면서 AI 브라우저가 이를 실행하도록 유도한다. 이는 AI 보안 영역에서 새로운 종류의 위협으로 평가받고 있다.
프롬프트 주입(Prompt Injection)은 사용자가 작성하지 않은 텍스트가 AI 봇에 명령어로 인식되는 현상이다. 직접 주입이 입력 창을 통해 이루어진다면, 간접 주입은 AI가 요약하도록 요청받은 웹 페이지나 PDF 등의 콘텐츠에 숨겨진 명령어를 AI가 사용자의 명령처럼 따르는 방식이다. AI 브라우저와 같은 새로운 유형의 웹 브라우저는 사용자 의도를 추측하여 자율적인 행동을 취하려고 시도하는 과정에서 특히 간접 프롬프트 주입에 취약하다는 것이 입증되어 왔다.
URL 단편(Fragment)을 무기화하여 방어망 우회
카토 네트워크는 해시잭을 "합법적인 웹사이트를 무기화하여 AI 브라우저 비서를 조작할 수 있는 최초로 알려진 간접 프롬프트 주입 공격"이라고 설명한다. 공격자들은 엣지의 코파일럿, 크롬의 제미나이 비서, 퍼플렉시티의 코멧과 같은 AI 브라우저 비서가 처리하는 합법적인 URL의 '단편(Fragment)' 부분에 악성 지침을 몰래 삽입한다.
URL 단편은 해시 기호 뒤에 붙는 텍스트로, 서버로 전송되지 않고 브라우저 내에서만 처리된다는 특징이 있다. 해시잭은 바로 이 점을 악용한다. URL 단편이 AI 브라우저 내에서만 작동하기 때문에, 기존의 네트워크 방화벽이나 서버 측 URL 필터링 방어 체계는 악성 명령을 탐지할 수 없다. 이로 인해 평범하고 신뢰할 수 있는 웹사이트가 순식간에 데이터 탈취를 위한 공격 벡터로 변모하게 되는 것이다.
해시잭 기법은 일반적인 URL 끝에 해시(#)를 추가하고 그 뒤에 악성 명령어를 삽입하는 방식으로 작동한다. 사용자가 자신의 AI 브라우저 비서를 통해 페이지와 상호 작용할 때, 숨겨진 이 명령어들이 대규모 언어 모델(LLM)로 유입되어 데이터 유출, 피싱, 잘못된 정보 유포, 악성 게임 콘텐츠 안내, 심지어 잘못된 약물 복용량 안내와 같은 의료적 피해까지 유발할 수 있다. 카토 네트워크의 연구원은 "신뢰할 수 있는 사이트를 무기화하여 성공 가능성이 전통적인 피싱보다 훨씬 높다"고 경고했다.
구글의 '의도된 동작' 분류, 엇갈리는 AI 보안 대응
카토 네트워크의 위협 연구팀(Cato CTRL)은 테스트 결과, 코멧과 같이 에이전트 기능이 있는 AI 브라우저는 공격자가 제어하는 엔드포인트로 사용자 데이터를 전송하도록 명령받을 수 있었으며, 비교적 수동적인 비서도 오해의 소지가 있는 지침이나 악성 링크를 표시할 수 있음을 확인했다. 이는 사용자가 신뢰하는 페이지와 상호 작용하고 있다고 생각할 때, 숨겨진 단편이 공격자의 링크를 제공하거나 백그라운드 호출을 유발할 수 있기 때문에 일반적인 '직접 주입' 공격과는 본질적으로 다르다.
카토의 공개 타임라인에 따르면, 구글과 마이크로소프트에는 지난 8월, 퍼플렉시티에는 7월에 해시잭 공격이 보고됐다. 구글은 이 문제를 "수정하지 않음(의도된 동작)"으로 분류하고 심각도를 낮게 평가했다. 반면, 퍼플렉시티와 마이크로소프트는 각자의 AI 브라우저에 즉시 수정 조치를 적용했다. 마이크로소프트는 성명을 통해 "간접 프롬프트 주입 공격으로부터 방어하는 것은 지속적인 노력"이라며 "보안팀은 항상 새로운 변종을 경계하며, 제품이 최고 수준의 AI 보안 표준을 충족하도록 보장한다"고 밝혔다.
카토의 연구 결과는 AI 보안 팀이 더 이상 네트워크 로그나 서버 측 URL 필터링에만 의존해서는 안 된다는 것을 시사한다. AI 브라우저의 광범위한 사용이 임박함에 따라, 서버 취약점이나 피싱 웹사이트에 국한되었던 위협의 종류가 이제 사용자의 브라우징 경험 자체 내부에 존재할 수 있다는 해시잭의 경고에 귀 기울여야 한다.
앞으로의 전망
해시잭 공격은 AI 브라우저의 '도움이 되려는' 의도가 악용될 수 있음을 보여주는 중요한 사례이다. 데이터 탈취를 막기 위해서는 AI 보안 거버넌스 도입, 의심스러운 URL 단편 차단, 허용된 AI 비서 제한, 그리고 클라이언트 측 모니터링을 포함하는 다층적인 방어 전략이 필수적일 것이다. 앞으로 AI 브라우저와 LLM의 결합이 심화되면서, 이처럼 사용자 경험에 깊숙이 숨어드는 새로운 유형의 AI 보안 위협이 지속적으로 등장할 것이다.
