
거대 언어 모델(LLM) 경쟁이 초고속으로 치닫는 가운데, 앤트로픽(Anthropic)이 플래그십 인공지능 모델인 'Opus 4.5'를 25일(현지 시간) 공개했다. 이는 지난 9월 Sonnet 4.5와 10월 Haiku 4.5를 선보인 앤트로픽의 4.5 시리즈 중 가장 강력한 모델이다. 이번 Opus 4.5 출시로 앤트로픽은 선두 주자인 오픈AI의 GPT 5.1과 구글 제미나이 3라는 강력한 경쟁자들에게 정면으로 도전한다.
SWE-Bench 80% 돌파, 코딩 AI 성능의 새로운 기준
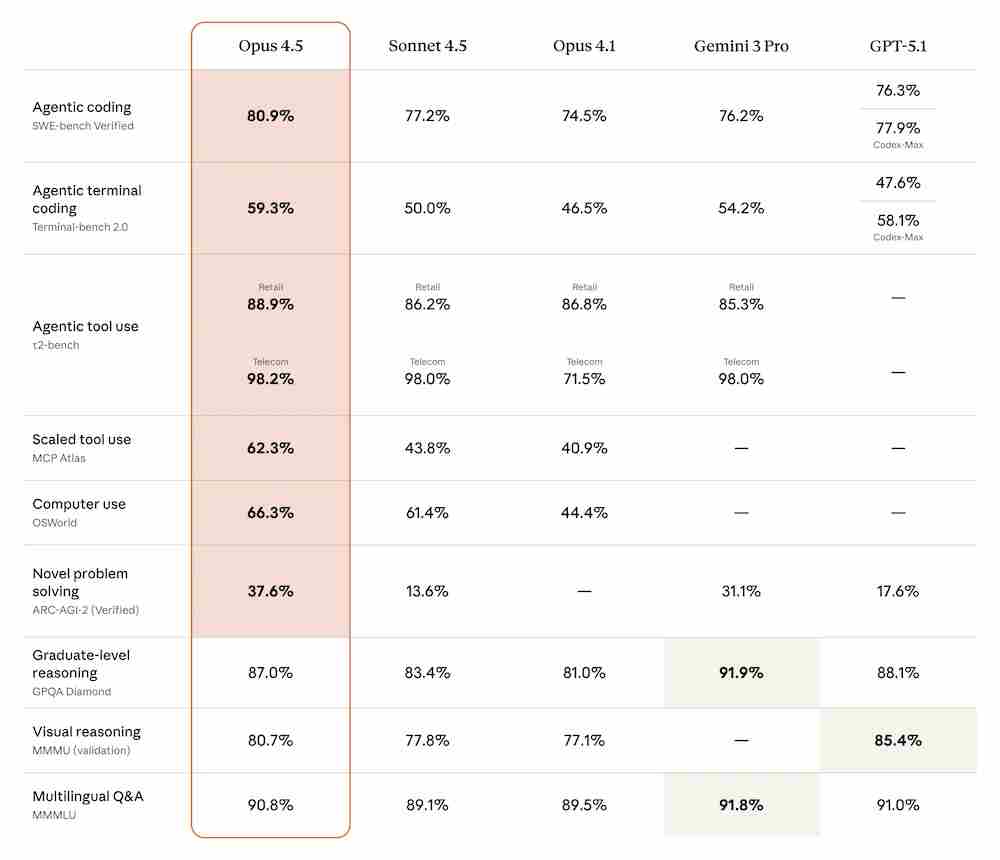
Opus 4.5는 코딩 벤치마크(SWE-Bench 및 Terminal-bench), 도구 사용(tau2-bench), 일반 문제 해결(GPQA Diamond) 등 여러 권위 있는 지표에서 최신 기술 수준의 압도적인 성능을 입증했다. 특히 기술 커뮤니티의 이목을 끈 부분은 코딩 성능이다. Opus 4.5는 소프트웨어 개발 작업을 평가하는 존경받는 벤치마크인 SWE-Bench 검증에서 업계 최초로 80%를 초과하는 점수를 달성했다. 이는 코딩 AI 분야에서 혁신적인 진전으로 평가되며, 실제 소프트웨어 개발 환경에서의 활용 가능성을 크게 높였다.
앤트로픽은 모델의 컴퓨터 사용 및 스프레드시트 처리 능력을 중점적으로 강조하고 있다. 이에 발맞춰 파일럿 단계였던 ' Claude for Chrom' 확장 프로그램과 엑셀 전용 모델인 'Claude for Excel'의 상용화 범위를 넓혔다. 크롬 확장 프로그램은 유료 구독자 모두에게 제공되며, 엑셀 특화 모델은 팀 및 엔터프라이즈 고객까지 이용이 가능해졌다. 이는 인공지능 모델이 단순한 질의응답을 넘어, 사용자의 일상적인 컴퓨팅 환경에 깊숙이 통합되도록 하려는 전략이다.
장기 기억력 혁신과 AI 에이전트 활용 전략
Opus 4.5의 또 다른 핵심 진보는 장기 컨텍스트(Long-Context) 작업 처리를 위한 메모리 관리 기술의 대대적인 개선이다. 앤트로픽의 연구 제품 관리 책임자인 다이앤 나 펜(Dianne Na Penn)은 "단순히 컨텍스트 윈도우(기억 창)의 길이를 늘리는 것만으로는 충분치 않다"며, "기억해야 할 적절한 세부 정보를 선별적으로 아는 것이 보완책으로서 중요하다"고 언급했다.
이러한 메모리 관리의 근본적인 변화는 AI 에이전트 활용 사례를 염두에 둔 조치이다. 특히 Opus가 리드 에이전트(Lead Agent) 역할을 맡아 Haiku 기반의 하위 에이전트들을 지휘하여 복잡한 프로젝트를 수행할 때, 강력한 '작업 기억력(Working Memory)'이 필수적이다. 또한 유료 사용자들을 위해 모델이 컨텍스트 윈도우 한계에 도달해도 사용자에게 알림 없이 메모리를 압축하며 대화를 지속하는 '끝없는 채팅(Endless Chat)' 기능도 추가됐다.
앞으로의 전망
앤트로픽의 Opus 4.5는 지난 11월 12일 출시된 오픈AI의 GPT 5.1과 11월 18일 공개된 구글 제미나이 3와의 기술 경쟁에서 밀리지 않겠다는 의지를 보여준다. 앞으로 거대 언어 모델 시장은 단순한 지능 대결을 넘어, 코드 베이스 탐색이나 대규모 문서 분석처럼 복잡한 업무를 능동적으로 수행하는 전문화된 AI 에이전트 기능을 얼마나 완벽하게 구현하는지에 따라 승패가 갈릴 것이다.
